Java로 진행되는 많은 프로젝트들이 iBatis를 이용하여 진행될 것이다. iBatis를 사용해본 사용자라면 iBatis를 사용하기 위해 생성해야 하는 DTO, DAO, SqlMap들을 만드는 것이 귀찮은 작업이라는 것은 다들 느낄 것이다. 나또한 DTO를 생성하는 것이 제일 귀찮으니 ...
그래서 iBatis 관련 소스 Generator를 만들까 고민하다 iBatis에서 제공하는 Abator이란 것을 발견하고 간단히 사용해 보니 쓸만해서 소개를 한다. 물론 생성 된 소스를 조금은 수정을 해야 한다.
그럼 Abator를 간략하게 들여다 보자.
-- Abator 다운로드
Abator 공식 사이트에서 소스와 Documents, Binaries를 다운받아 적당한 위치에 압축을 푼다.
-- iBatis 소스 생성하기
Abator Plugin은 간단하게 말하면 DataBase에 접속하여 지정 된 Table에 대한 DTO, Key, DAO, SqlMap 소스를 자동으로 생성해 준다. Abator을 이용하여 iBatis 소스를 생성하는 방법은 간단하다. abator의 config xml file을 생성하고 ant를 이용하여 실행하면 된다.
abator_config.xml file
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE abatorConfiguration PUBLIC "-//Apache Software Foundation//DTD Abator for iBATIS Configuration 1.0//EN" "http://ibatis.apache.org/dtd/abator-config_1_0.dtd">
<abatorConfiguration>
<abatorContext id="Oracle">
<!-- DataBase 연결정보 정의 -->
<jdbcConnection driverClass="oracle.jdbc.driver.OracleDriver"
connectionURL="jdbc:oracle:thin:@192.160.100.204:1521:devora"
userId="backend" password="!Qprdpsem@">
<classPathEntry location="xxx/ojdbc14.jar" />
</jdbcConnection>
<javaTypeResolver>
<property name="forceBigDecimals" value="false" />
</javaTypeResolver>
<!-- 모델빈의 위치및 생성옵션 (DTO 생성) -->
<javaModelGenerator targetPackage="com.junducki.blog.ibatis.dto" targetProject="../blog/src/main/java">
<property name="enableSubPackages" value="true" />
<property name="trimStrings" value="true" />
</javaModelGenerator>
<!-- SqlMap 생성 -->
<sqlMapGenerator targetPackage="pay" targetProject="../blog/src/main/java/sql">
<property name="enableSubPackages" value="true" />
</sqlMapGenerator>
<!-- DAO 생성옵션 -->
<daoGenerator type="SPRING" targetPackage="com.junducki.blog.ibatis.dao"
targetProject="../blog/src/main/java">
<property name="enableSubPackages" value="true" />
<property name="useActualColumnNames" value="false" />
</daoGenerator>
<!-- 소스생성에 필요한 테이블들을 지정한다. -->
<table tableName="TB_PAY_INFO" domainObjectName="PayInfo" enableDeleteByExample="false"
enableSelectByExample="false" enableUpdateByPrimaryKey="false" enableInsert="false">
<property name="useActualColumnNames" value="false" />
<property name="createDynamicSQL" value="true" />
</table>
</abatorContext>
</abatorConfiguration>
build.xml file
<?xml version="1.0" encoding="UTF-8" ?>
<project name="blog" default="geniBatis" basedir=".">
<property name="generated.source.dir" value="${basedir}" />
<target name="geniBatis" description="Generate iBatis">
<taskdef name="abator" classname="org.apache.ibatis.abator.ant.AbatorAntTask"
classpath="lib/abator.jar" />
<abator overwrite="true" configfile="../ibatis_plugin/abator_config.xml" verbose="false">
<propertyset>
<propertyref name="generated.source.dir" />
</propertyset>
</abator>
</target>
</project>
위의 abator_config.xml과 build.xml 파일을 이용하여 생성한 iBatis 소스들은 아래와 같다.
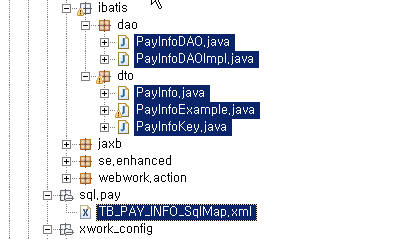
[ Abator을 이용해 iBatis 소스 생성 결과 ]
DTO : PayInfo, PayInfoKey
SqlMap : TB_PAY_INFO_SqlMap.xml
이와 같이 Abator를 이용하면 아주 간단히 iBatis 관련 소스를 실제 DataBase와 매핑하여 생성할 수 있다. 그리고, 여기서는 아주 간단하게 Abator을 다루어 보았는데, Abator Document를 보면 configuration 설정에 더욱 많으니 꼭 보기 바란다.
